

私は今まで、何度か転職を経験し、上場企業およびベンチャー企業等の上場準備会社で20年以上経理財務業務を行ってきました。その会社の経理業務の品質・信頼性を高めるためには、正確性と効率性の両方を上げていく必要があり、そのために経理作業の自動化は欠かせません。その中で、非常に有効性が高い経理業務とPythonの組み合わせについて、私が実際に活用した事例をご紹介したいと思います。
ここでは、Pythonをつかって、WEBスクレイピングを行い、ウェブページからデータを取得し、所定のフォルダに格納する迄の一連の作業を自動化させる方法をいくつかご紹介します。
いずれも、コーディングしようとしたときに、書籍やGoogle等で色々調べ、試行錯誤して完成したコードです。非常に有効だと思いますので、是非ご活用ください。
- Pythonで始めるWebスクレイピングの基礎
- Seleniumを使うための環境設定
- ChromeDriverのセットアップ方法
- Seleniumの基本的使用手順
- 経理業務に役立つseleniumを使ったWebスクレイピングの具体例
- 要素が取得できないときの原因と対処法
- WEBスクレイピングを定期実行する方法
- 最後に
Pythonで始めるWebスクレイピングの基礎
Webスクレイピングは、インターネット上に公開されている情報を自動的に抽出する手法で、Pythonはその柔軟性と簡潔な文法により、スクレイピングに非常に適したプログラミング言語です。スクレイピングには、主に以下のライブラリが利用されます。
requests: サイトからHTMLページを取得するためのライブラリ。BeautifulSoup: HTMLやXMLを解析してデータを抽出するためのライブラリ。Selenium: JavaScriptで動的にコンテンツが読み込まれるページを操作するために使用されるツール。
Pythonを使った基本的なスクレイピングでは、まずウェブページを取得し、必要な情報を取り出すためにHTMLを解析します。requestsでウェブページのHTMLを取得し、BeautifulSoupで解析を行うという流れです。Seleniumは、ブラウザの自動操作を可能にするツールで、ウェブサイトから自動的にCSV等のデータを取得することが出来ます。
経理業務においては、ウェブサイトからデータをダウンロードし、加工のうえ、会計システムに取り込むことが多いと思いますが、その一連の操作をSeleniumを使って自動化させることでかなり効率化させることが出来ますので、経理業務でWEBスクレイピングを活用するのであれば、Seleniumを使うのがおすすめです。
Seleniumを使うための環境設定
Seleniumを使うためには、まず環境設定を行う必要があります(Python、およびエディタはインストール済の前提です)。
環境設定の手順は以下の通りです。
Seleniumのインストール
Seleniumは、Pythonのパッケージマネージャであるpipを使ってインストールできます。
エディタで次のコマンドを実行すればインストールされます。
pip install seleniumブラウザのドライバを準備する
Seleniumは、実際のブラウザ(ChromeやFirefoxなど)を操作します。そのため、使用するブラウザに対応する「WebDriver」が必要です。例えば、Google Chromeの場合、ChromeDriverをダウンロードし、セットアップする必要があります。
ブラウザのバージョンを確認する
使用しているChromeのバージョンに適したChromeDriverをダウンロードします。Chromeのバージョンは、ブラウザの「設定」から確認できます。
Seleniumとブラウザドライバの接続
WebDriverを使用してPythonコードからブラウザを起動し、操作します。基本的なコードは次の通りです。
from selenium import webdriver # WebDriverのパスを指定してブラウザを起動
driver = webdriver.Chrome(executable_path='/path/to/chromedriver')
driver.get('https://example.com')ChromeDriverのセットアップ方法
上記のとおり、ChromeDriverをダウンロードする必要がありますが、もう少し詳しくその具体的方法およびセットアップ方法についてお伝えしたいと思います。
Chromeブラウザのバージョン確認
まず、使用しているGoogle Chromeブラウザのバージョンを確認する必要があります。ChromeDriverはChromeブラウザのバージョンに合わせて適切なバージョンをダウンロードする必要があります。
- バージョン確認方法:
- Google Chromeを開きます。
- 右上の「︙」アイコンをクリックし、「ヘルプ」 > 「Google Chromeについて」を選択します。
- 表示される画面で、Chromeのバージョンが確認できます。
ChromeDriverのダウンロード
次に、ChromeDriverのバージョンをChromeブラウザに合わせてダウンロードします。
- ダウンロード手順:
- ChromeDriverの公式サイトにアクセスします。
- サイトに表示されている「ChromeDriver – WebDriver for Chrome」のページに行き、自分のブラウザのバージョンと一致するChromeDriverを探します。例えば、Chromeブラウザがバージョン
90.x.xxxx.xxであれば、ChromeDriverもそのバージョンを選んでダウンロードします。 - ダウンロードリンクをクリックし、対応するOS(Windows、macOS、Linux)用のバージョンを選択してダウンロードします。
ChromeDriverのインストール
ChromeDriverのファイルをダウンロードしたら、それを解凍して適切な場所に配置する必要があります。
- インストール手順:
- ダウンロードしたファイル(通常はZIPファイル)を解凍します。
- 解凍後、
chromedriver.exe(Windowsの場合)またはchromedriver(macOS/Linuxの場合)という実行可能ファイルが生成されます。 - これをシステムの適切なディレクトリ(例えば、
C:\chromedriverや/usr/local/bin)に配置します。
Pythonファイルと同じディレクトリに配置しておくとよいと思います。
Seleniumの基本的使用手順
以上で、Seleniumを使うための環境構築はできました。
次に、Seleniumの基本的使用手順についてお伝えしたいと思います。
ウェブサイトにおける要素の指定方法
Seleniumで必要なデータを抽出するためには、HTML要素を正確に指定する必要があります。これには、Chromeの「検証」機能や「検査対象となる要素の選択」ボタンを活用する方法が非常に有効です。以下ではその手順と、要素を特定する方法について詳しく説明します。
ウェブサイトを開く
最初にSeleniumを使ってウェブサイトを開きます。例えば、Google Financeで株価を取得する場合、以下のようにコードを書きます。
driver = webdriver.Chrome(executable_path='/path/to/chromedriver')
driver.get('https://www.google.com/finance/quote/GOOG:NASDAQ') 「executable_path='/path/to/chromedriver‘」
の部分は、ダウンロードしたChromeDriverを保存した場所を指定します。
右クリック「検証」からHTMLコードを表示する
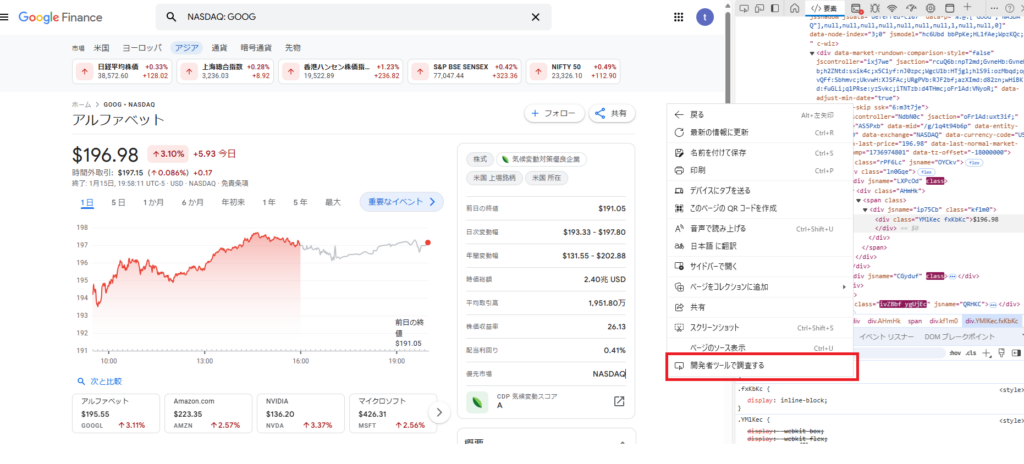
ウェブページを開いた後、データがどのHTML要素に格納されているかを確認するため、まず右クリックをして「検証」(「開発者ツールで調査する」)を選択します。これにより、ブラウザの開発者ツールが表示され、ページのHTMLコードが表示されます。
左上の「検査対象となる要素の選択」ボタンを使い、要素を特定する
左上にある「検査対象となる要素の選択」ボタンをクリックすることで、ページ上のどの要素でも簡単に特定できるようになります。手順は以下の通りです
- 開発者ツールの左上にあるアイコン(虫眼鏡のようなアイコン)をクリックします。
- ページ内で検査したい要素(例えば株価を表示している部分)をクリックします。これにより、その要素のHTMLコードが開発者ツール内でハイライト表示され、どのタグや属性がそのデータを示しているかが分かります。
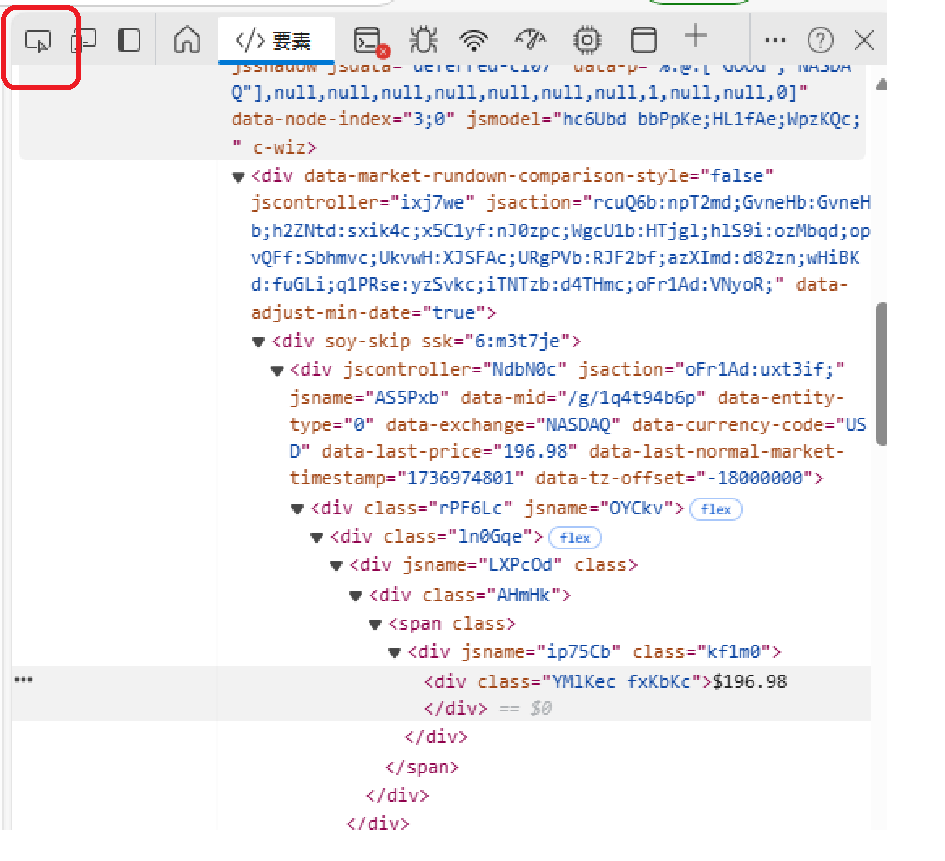
特定した要素の指定方法
特定した要素をSeleniumで指定するためには、さまざまな方法があります。
上記の方法で特定したHTML部分を見て、指定する部分を確認します。
以下に代表的な方法を示します。
- IDで指定
HTML要素にID属性がある場合、そのIDを指定して要素を取得できます。
element = driver.find_element(By.ID,’×××’) - クラス名で指定
クラス名を使って要素を取得できます。
element = driver.find_element(By.CLASS_NAME,’×××’) - XPATHで指定
XPATHはHTMLツリーをもとに要素を指定する強力な方法です。
element = driver.find_element(By.XPATH,’×××’) - CSSセレクタで指定
CSSセレクタを使って要素を指定することも可能です。
element = driver.find_element(By.CLASS_SELECTOR,’×××’)
これらの方法を使って、ウェブページ上の特定の要素を指定します。
ただし、私は、ほとんどの場合、「XPATHで指定」します。これはどの場合でも使うことができ、あまり悩まずにすむからです。
次にXPATHの取得の仕方をお伝えします。
XPATHの取得の仕方
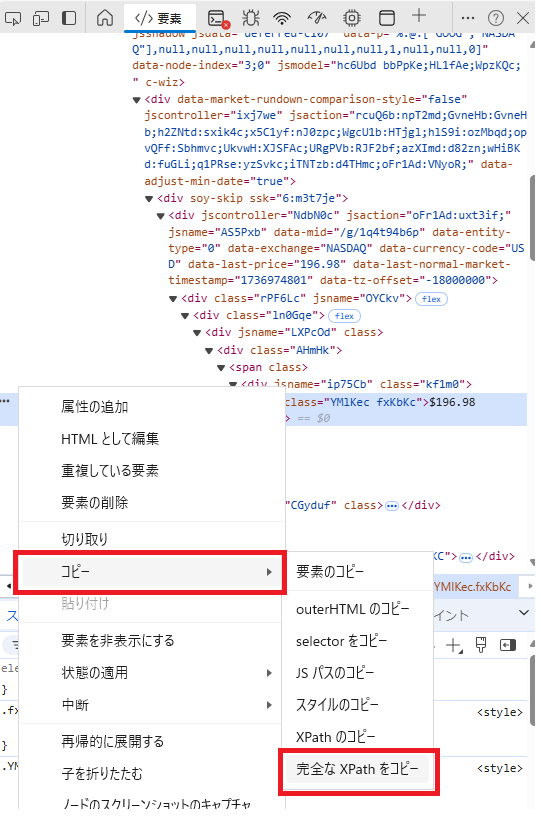
XPATHの取得は次の手順で行うことができます。
- 上記方法でウェブページ上の要素を特定できたら、その要素の箇所で右クリックします。
- 次に「コピー」⇒「完全なXPathをコピー」をクリックします。
- element = driver.find_element(By.XPATH,’×××’)
の×××の箇所に貼り付けします。
実際に株価を取得する
ここでは、Google Financeのページから株価を取得する方法を具体的に示します。
開発者ツールでXPATHを確認した後、Seleniumでそのデータを抽出するコードを以下に示します。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverを起動
driver = webdriver.Chrome(executable_path='/path/to/chromedriver')
# Google Financeのページを開く
driver.get('https://www.google.com/finance/quote/GOOG:NASDAQ')
# XPathを使って株価を取得
stock_price = driver.find_element(By.XPATH, '//*[@data-test="OPEN-value"]').text print(f"株価: {stock_price}")
# ブラウザを閉じる
driver.quit()
上記のコードでは、XPath '//*[@data-test="OPEN-value"]' を使用して、Google Financeの株価情報を取得しています。textを使うことで、株価の値を文字列として抽出できます。
動的に変化するデータの取得
Seleniumを使うと、JavaScriptで動的に変化するデータにも対応できます。たとえば、株価はリアルタイムで更新される場合があります。これを取得するには、以下のように待機処理を加えて最新の情報を取得します。
# ページの読み込みを待つ
driver.implicitly_wait(10) # 最大10秒間待機
# 動的に更新された株価を取得
updated_stock_price = driver.find_element(By.XPATH, '//*[@data-test="OPEN-value"]').text print(f"更新された株価: {updated_stock_price}") implicitly_wait()を使うことで、ページの読み込みや動的に変化する要素の読み込みを待機し、最新のデータを取得することができます。
経理業務に役立つseleniumを使ったWebスクレイピングの具体例
経理業務において、Seleniumを使ったWebスクレイピングは、定期的に必要な株価や経済指標、取引明細などを自動で収集するために非常に役立ちます。
スクレイピングで収集したデータは以下のように活用できます:
- 株価データの収集: 収集した株価データを基に、月次報告書や投資ポートフォリオの分析を自動化できます。
- 為替レートの収集: 外貨建ての取引が多い企業では、定期的に為替レートを取得し、取引レポートに自動的に反映させることができます。
- 取引明細取得: 特定のウェブサイトから取引明細を自動でダウンロードし、経理処理に活用することができます。
Seleniumを活用することで、手動で行っていた情報収集の作業を効率化し、経理部門の業務を大幅に改善することができます。
以下、実際にプログラミングを行い、活用しているPythonコードをご紹介します。
Selenium Webページへのログイン、データ取得を自動化する方法
経理部では、毎月、管理画面にログインし、店舗毎の取引明細のCSVデータ・PDFデータをダウンロードし、取引の確認および加工のうえ会計システムに取り込み、起票を行っています。店舗毎に画面を切り替え、複数の帳票を取得するのは結構時間がかかります。また、ダウンロードするだけでなく、そのダウンロードしたファイルに適切な名前を付し、所定のフォルダに格納しています。
それら一連の作業を全て自動化することで、かなりの効率化を実現できました。
以下、その方法をご紹介いたします。
ID、パスワードの入力、ログインおよびデータダウンロードの自動化
Seleniumを使って、ウェブページにログインするコード例は次のとおりです。管理画面にログインし、「請求書CSVデータ」「債務確定通知書CSVデータ」「精算書PDFデータ」をダウンロードする一連の作業を自動化する内容になっています。
環境設定のうえ、こちらのコードをコピーし、×××の箇所にURL、特定した要素を入力し実行すれば、ログインまでが自動で行うことができます。
ただし、インポートするモジュールやパッケージが未だインストールされていない場合は、ターミナルで「pip install ×××」のコマンドを実行し、インストールすることが必要です。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select # Selectをインポート
from selenium.webdriver.common.action_chains import ActionChains
from time import sleep
import os
import shutil
# 月指定
month = "2025.1"
#ダウンロードフォルダパス指定
downloadsdir_path = '×××'
# Chromeオプションを設定
options = webdriver.ChromeOptions()
options.add_experimental_option('detach', True) # ブラウザが閉じないように設定
# ChromeDriverのサービスを設定
cService = Service(executable_path='×××')
driver = webdriver.Chrome(service=cService, options=options)
actionChains = ActionChains(driver)
# 暗黙的な待機時間を設定
driver.implicitly_wait(10)
# ログインページを開く
url_login = '×××'
driver.get(url_login)
try:
# ID入力
text_box = driver.find_element(By.NAME, '×××')
text_box.send_keys('×××')
sleep(5)
# パスワード入力
text_box = driver.find_element(By.NAME, '×××')
text_box.send_keys('×××')
# ログインボタンをクリック
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(10)
# 個別施設管理画面
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
# 施設選択
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
# 請求管理
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
# 精算確認画面
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
# 請求書CSVデータダウンロード
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
data = "請求書.csv"
files = os.listdir(downloadsdir_path)
path_dir = os.path.join(downloadsdir_path,*files)
movebase_dir = R"×××"
move_dir = os.path.join(movebase_dir,month,data)
shutil.move(path_dir,move_dir)
# 債務確定通知書CSVデータダウンロード
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
data = "売掛金額.csv"
files = os.listdir(downloadsdir_path)
path_dir = os.path.join(downloadsdir_path,*files)
movebase_dir = R"×××"
move_dir = os.path.join(movebase_dir,month,data)
shutil.move(path_dir,move_dir)
# 債権確定通知書PDFデータダウンロード
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
data = "手数料.pdf"
files = os.listdir(downloadsdir_path)
path_dir = os.path.join(downloadsdir_path,*files)
shutil.move(path_dir,move_dir)
# 精算書PDFデータダウンロード
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
#ブラウザを閉じる
driver.quit()
except Exception as e:
print(f"エラーが発生しました: {e}")
# スクリプト終了を防ぐ
input("終了するには Enter キーを押してください...")Selenium 画面スクリーンショットの自動化
PythonのSeleniumライブラリを活用することで、スクリーンショットの自動化が簡単に行えます。さらに、取得した情報をPDF形式で保存すれば、帳票保存やレポート作成の手間を削減できます。PythonとSeleniumを使用したWebスクレイピングの活用により、スクリーンショットの自動取得、データのPDF保存までの具体的な方法を、実際のコード例を交えて解説します。
スクリーンショット自動化を活用するシナリオ
ウェブページの全体または一部をスクリーンショットして、それを帳票や監査資料としてPDF保存することも多いと思います。経理業務において、スクリーンショットを利用するシナリオは次の様なものがあります。
- 証跡の保存(Webページの状態を記録)
- 監査用のデータとして利用
- 自動レポート作成の一部として活用
Seleniumでスクリーンショットを撮る方法
特定要素のスクリーンショットを撮る方法
特定要素のみスクリーンショットを撮る方法は簡単です。
要素を指定して「element.screenshot(‘element_screenshot.png’)」のコマンドを実行すれば可能です。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://×××')
element = driver.find_element(By.ID, '×××')
element.screenshot('element_screenshot.png')
driver.quit()ただ、要素のみスクリーンショットを撮ることはほとんどないと思いますので、以下、実用的な方法を説明します。
画面全体をスクリーンショットする方法
現在のディスプレイに表示されている画面全体をスクリーンショットをする方法は次のとおりです。
from selenium import webdriver
from selenium.webdriver.common.by import By
import pyautogui
driver = webdriver.Chrome()
driver.get('https://×××')
# 画面全体のスクリーンショットを取得
img_full = pyautogui.screenshot()pyautogui の screenshot() メソッドを使用します。
この様にすれば、画面全体を撮ることができますので、実用的です。
ただ、画面全体ではなく、特定部分のみのスクリーンショットを撮り保存することの方が実務ではニーズが多いと思います。
次に範囲を指定しスクリーンショットする方法を説明します。
スクリーンショットの範囲を指定する方法
from selenium import webdriver
from selenium.webdriver.common.by import By
import pyautogui
driver = webdriver.Chrome()
driver.get('https://×××')
# スクリーンショットの範囲を指定
prtsc_range = (500, 200, 1000, 800)
# スクリーンショットの取得
img1 = pyautogui.screenshot(region=prtsc_range)「prtsc_range = (500, 200, 1000, 800)」の部分を適宜変更して、スクリーンショットする範囲を調整してください。
この様にすれば、取得したい部分のみスクリーンショットすることができるので、一番実用的だと思います。
Selemiumでダウンロードしたファイルのリネームと所定フォルダへの移動を自動化
経理業務では、請求書や領収書、取引データのファイルを日々ダウンロードし、フォルダごとに整理する作業が発生します。これらを手作業で行うと、時間がかかるだけでなく、ヒューマンエラーのリスクも高まります。
Pythonを活用すれば、ウェブページからのファイルダウンロード、ダウンロードしたファイルのリネーム、および所定のフォルダへの移動を全て自動化させることが可能です。
Pythonを使ったファイル管理の自動化手法を詳しく解説します。
Pythonを使ったファイル管理の基本操作
Pythonでファイルをリネームし、フォルダに移動するためには、以下のモジュールを活用します。
- os:ファイルやフォルダの操作
- shutil:ファイルの移動やコピー
- glob:特定のファイルを検索
以下のコードで、ダウンロードフォルダ内のPDFファイルを自動でリネームし、指定フォルダへ移動できます。
import os
import shutil
import glob
# ダウンロードフォルダのパス
downloadsdir_path = "C:/Users/Username/Downloads"
# 移動先フォルダ
movebase_dir = "C:/Users/Username/Documents/経理ファイル"
# ファイルの検索
files = glob.glob(os.path.join(downloadsdir_path, "*.pdf")) # PDFファイルのみ対象
for file_path in files:
filename = os.path.basename(file_path)
new_filename = "invoice_" + filename # 例: "invoice_12345.pdf" にリネーム
new_path = os.path.join(movebase_dir, new_filename)
shutil.move(file_path, new_path)
print(f"Moved: {file_path} → {new_path}")このスクリプトを実行すると、ダウンロードフォルダ内のPDFファイルがリネームされ、指定の経理用フォルダに自動的に移動します。
Seleniumによりダウンロードしたファイルを一つずつリネームし所定のフォルダに移動させる方法
Seleniumにより自動でファイルをダウンロードした場合、ダウンロードファイルは一つではなく、複数であるケースがほとんどだと思います。
一つのファイルまたは複数ファイルを一括でリネームし移動させるには上記方法でOKですが、実務では、一つずつ適切な名前に変更することが必要な場合がほとんどだと思います。
以下のコードで、ダウンロードしたファイルを一つずつリネームし、指定フォルダへ移動させることができます。
#ダウンロードフォルダのパス
downloadsdir_path = "C:/Users/Username/Downloads"
# 移動先フォルダ
movebase_dir = "C:/Users/Username/Documents/経理ファイル"
#実績一覧ファイルダウンロード
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
#リネームするファイル名を指定
data = "0470_〇〇店_実績一覧.csv"
#フォルダ移動
files = os.listdir(downloadsdir_path)
path_dir = os.path.join(downloadsdir_path,*files)
move_dir = os.path.join(movebase_dir,data)
shutil.move(path_dir,move_dir)「files = os.listdir(downloadsdir_path)」:ダウンロードフォルダにダウンロードされたファイル名を取得します。
「path_dir = os.path.join(downloadsdir_path,*files)」:そのファイルのファイルパスを取得することができます。
「move_dir = os.path.join(movebase_dir,data)」:移動先のファイルパスを指定します。
「shutil.move(path_dir,move_dir)」:ダウンロードフォルダから移動先フォルダにファイルを移動させます。
Selenium 別のウィンドウが立ち上がる場合の対処法
新しいウィンドウに操作を切り替える方法
Selemiumでブラウザ操作を自動化した場合、別のウィンドウが立ち上がり、そのままでは自動操作が出来なくなることがあります。
この様な場合「driver.switch_to.window」を使い、新しいウィンドウに操作を切り替える必要があります。
施設選択のボタンをクリックしたときに、別にウィンドウが立ち上がり、その新しいウィンドウでデータをダウンロードする例を次に示します。
# 施設選択
btn = driver.find_element(By.XPATH,×××')
btn.click()
sleep(10)
# 遷移先ページに移動
handle_array = driver.window_handles
driver.switch_to.window(handle_array[1])
# 精算明細書をダウンロード
btn = driver.find_element(By.NAME,"×××")
btn.click()
sleep(5)handle_array[0] が元々のウィンドウ、handle_array[1]が新しいウィドウを表します。したがって、新しいウィンドウに操作を切り替えるためには、handle_array[1]にスイッチします。
元のウィンドウに操作を切り替える方法
元のウィンドウに戻り操作を行う場合には、handle_array[0]にすればOKです。
次のケースでは、施設選択のウィンドウに戻り、別の施設を選択すると、2つ目のウィンドウが立ち上がり、そこでデータをダウンロードする例になります。
#施設選択の画面に戻る
driver.switch_to.window(handle_array[0])
#施設選択
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
# 遷移先ページに移動
handle_array = driver.window_handles
driver.switch_to.window(handle_array[2])
# 精算明細書をクリック
btn = driver.find_element(By.NAME,"×××")
btn.click() ファイルダウンロード、スクリーンショット、ファイルのリネームと所定フォルダへの移動 自動化のコード例
以下、上記で説明した全ての作業を自動化させたコード例をお伝えします。
是非、ご活用ください!
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select # Selectをインポート
from selenium.webdriver.common.action_chains import ActionChains
from time import sleep
import os
import shutil
import pyautogui
from PIL import Image
# 保存フォルダを指定
movebase_dir = "C:/Users/Username//Documents/経理ファイル"
#ダウンロードフォルダパス指定
downloadsdir_path = "C:/Users/Username/Downloads"
# Chromeオプションを設定
options = webdriver.ChromeOptions()
options.add_experimental_option('detach', True) # ブラウザが閉じないように設定
# ChromeDriverのサービスを設定
cService = Service(executable_path='.\chromedriver.exe') # クロームドライバーが保存されているフォルダを指定
driver = webdriver.Chrome(service=cService, options=options)
actionChains = ActionChains(driver)
#スクリーンショットの範囲を指定
prtsc_range = (500,200,1000,800) #必要に応じて変更
# 暗黙的な待機時間を設定
driver.implicitly_wait(10)
# ログインページを開く
url_login = 'https://www.×××' # URLを指定
driver.get(url_login)
try:
# ID入力
text_box = driver.find_element(By.XPATH, '×××')
text_box.send_keys('×××')
sleep(5)
# パスワード入力
text_box = driver.find_element(By.XPATH, '×××')
text_box.send_keys('×××')
# ログインボタンをクリック
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(10)
# 施設選択(〇〇店)
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(10)
# 遷移先ページに移動
handle_array = driver.window_handles
driver.switch_to.window(handle_array[1])
# 月選択
driver.switch_to.default_content()
btn = driver.find_element(By.XPATH,'×××')
btn.click()
btn = driver.find_element(By.XPATH,'×××')
btn.click()
#表示する
elem = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
#実績一覧ダウンロード
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
#リネームするファイル名を指定
data = "0470_〇〇店_実績一覧.csv"
#リネーム、フォルダ移動
files = os.listdir(downloadsdir_path)
path_dir = os.path.join(downloadsdir_path,*files)
move_dir = os.path.join(movebase_dir,data)
shutil.move(path_dir,move_dir)
#スクリーンショット、保存
data = 'screenshot.pdf' #PDF形式で保存
img1 = pyautogui.screenshot(region=prtsc_range)
file_path = os.path.join(movebase_dir,data)
img1.save(file_path)
#施設選択の画面に戻る
driver.switch_to.window(handle_array[0])
# 施設選択(△△店)
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(10)
# 遷移先ページに移動
handle_array = driver.window_handles
driver.switch_to.window(handle_array[2])
# 月選択
driver.switch_to.default_content()
btn = driver.find_element(By.XPATH,'×××')
btn.click()
btn = driver.find_element(By.XPATH,'×××')
btn.click()
#表示する
elem = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
#実績一覧ダウンロード
btn = driver.find_element(By.XPATH,'×××')
btn.click()
sleep(5)
#リネームするファイル名を指定
data = "0480_△△店_実績一覧.csv"
#リネーム、フォルダ移動
files = os.listdir(downloadsdir_path)
path_dir = os.path.join(downloadsdir_path,*files)
move_dir = os.path.join(movebase_dir,data)
shutil.move(path_dir,move_dir)
#スクリーンショット、保存
data = 'screenshot.pdf' #PDF形式で保存
img1 = pyautogui.screenshot(region=prtsc_range)
file_path = os.path.join(movebase_dir,data)
img1.save(file_path)
#ブラウザを閉じる
driver.quit()
except Exception as e:
print(f"エラーが発生しました: {e}")
# スクリプト終了を防ぐ
input("終了するには Enter キーを押してください...")
要素が取得できないときの原因と対処法
Seleniumを使って、ブラウザ操作を自動化させようとした場合、要素がうまく取得できないケースが多く発生します。
このケースに遭遇した場合、その原因を把握し、適切な対処を行う必要があります。
この原因および対処法については、こちらの記事で詳しく説明していますので、参考にしてください。
Python Seleniumで要素を取得できない場合の対処法:原因と解決策
WEBスクレイピングを定期実行する方法
WEBスクレイピングを業務で使用する場合、毎日あるいは毎週等、定期的に行う場合が多いと思います。
したがって、その定期実行も自動化させることで、さらなる効率化を図ることができます。
その方法について、こちらの記事で詳しく説明していますので、よろしければ、ご覧ください。
Python Seleniumを使ったWEBスクレイピングをWindowsタスクスケジューラで定期実行する方法(完全ガイド)
最後に
以上、WEBスクレイピングの活用例を説明しましたが、他にも、Excel関数およびPythonを使用することで、画期的な改善を行った多数の事例があります。このブログでは、実務に即した活用例をご紹介していますので、よろしければ、他の記事もご覧ください。
また、経理の方は、この様に、業務効率化に非常に有効なPythonを勉強してみてはいかがでしょうか。
関連記事で、Pythonの勉強方法についてもご紹介しています。こちらも是非ご覧ください!
文系未経験者がプログラミングを学ぶためにまず行うこと
Python3エンジニア認定基礎試験 文系未経験者が合格するために一番効率的な勉強の仕方


コメント