

私は今まで、何度か転職を経験し、上場企業およびベンチャー企業等の上場準備会社で20年以上経理財務業務を行ってきました。その中で、経理業務を効率化させるため、作業的な業務はなるべく自動化する取り組みを続けてきました。これらの経験を皆さんの業務においても活用できるようお伝えしていきたいと思います。
経理業務では、請求書や領収書、取引履歴の保存が欠かせません。多くの企業やサービスでは、Web上でこれらの情報を提供していますが、それらをCSVデータとしてダウンロードする他、画面をPDF保存することも多いと思います。ただ、手作業でPDFとして保存するのは手間がかかります。
そこで、PythonのSeleniumを活用し、Webページを自動的にPDFとして保存する方法を紹介します。これにより、請求書や取引明細の保存を自動化し、経理業務の効率を大幅に向上させることが可能です。
経理業務での活用ポイント
経理業務においては、次のようなWebページをPDFで保存するケースがあります。
- インターネットバンキングの取引明細
- 管理画面に表示される取引明細、入金内訳、請求書等
- オンラインショッピングの領収書 等
Seleniumを利用すれば、これらのWebページを自動的にPDFで保存できるため、手作業のミスを防ぎ、業務の効率化を実現できます。
Seleniumを使うための環境設定
Seleniumを使うためには、まず次の環境設定を行う必要があります。
- Seleniumのインストール
- ブラウザのドライバ(ChromeDriver)のセットアップをする
- Seleniumとブラウザドライバの接続
これらについては、こちらの記事で詳しく説明していますので、環境設定が未だの方はこちらをご覧ください。
経理業務でPythonのWEBスクレイピングを活用する方法と具体例
PythonでWebページをPDF保存
手動でWebページをPDF保存する方法
環境設定が完了したら、コードを入力し実行すれば、WebページのPDF保存を自動化することができます。
まず、Python Seleniumを使わず、手動でWebページのPDF保存のやり方を見てみましょう。
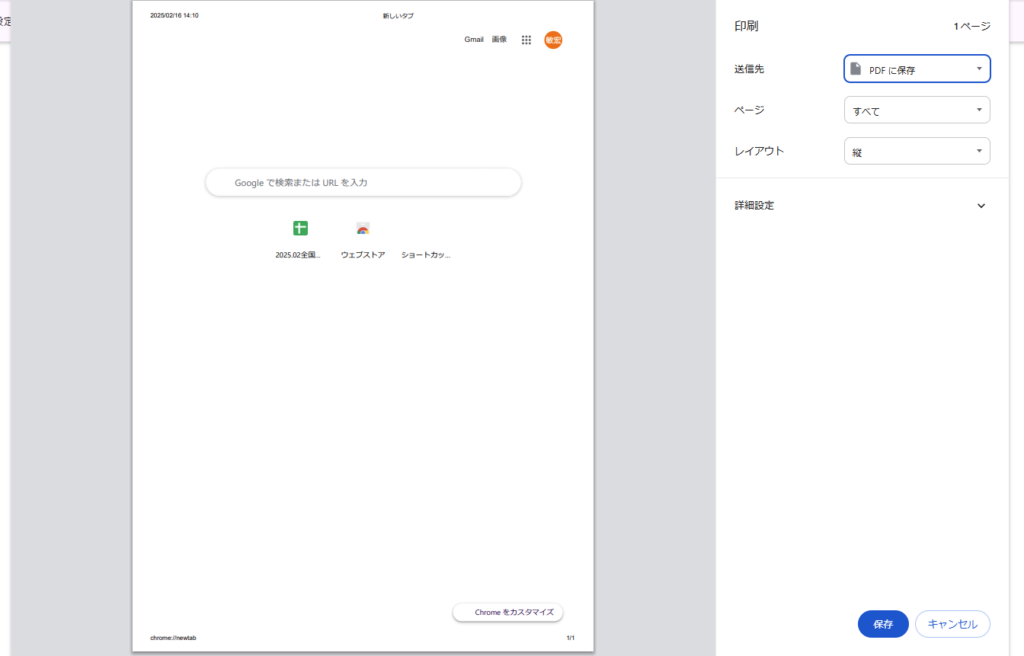
例えば、このGoogle検索画面をPDF保存しようとする場合、右クリック⇒印刷をクリックすると、印刷設定画面になります。

そして、送信先を「PDFに保存」として、「保存」をクリックすると、画面をPDF保存することができます。
Python SeleniumでWebページをPDF保存するコード例
では、次に、Python SeleniumでWebページをPDF保存する方法を説明します。
上で説明した手動で保存する手順をPython Seleniumで自動化させます。
印刷設定を行うコード例
次の様に、印刷設定を行うコードを記載する必要があります。
印刷設定のコード例は他のサイト・書籍等にもいろいろ紹介されていますが、なかなかうまく動くコードがなく、試行錯誤して実際に動くよう整理したコードです。
# 印刷設定
options.add_experimental_option('prefs', {
"printing.print_preview_sticky_settings.appState": json.dumps({
"recentDestinations": [{"id": "Save as PDF", "origin": "local"}],
"selectedDestinationId": "Save as PDF",
"version": 2,
"isLandscapeEnabled": True,
"isHeaderFooterEnabled": False,
"isCssBackgroundEnabled": True
}),
"savefile.default_directory": downloadsdir_path # PDF保存先を指定
})
options.add_argument('--kiosk-printing') # 印刷を自動実行PDF保存を実行するコード例
送信先をPDF保存にし、印刷を実行するコード例です。
# PDF保存
WebDriverWait(driver, 15).until(EC.presence_of_all_elements_located) # ページ上のすべての要素が読み込まれるまで待機
driver.execute_script('window.print()') # 印刷を実行
time.sleep(10) # ファイルのダウンロードのために10秒待機 画面にログインし、WebページをPDF保存する一覧のコード例
以下のコードは、管理画面にログインし、指定したWebページを自動で開き、PDFとして保存するコード例です。
ここでは、入金明細CSVデータをダウンロードし、さらにそのWebページをPDF化し、CSVデータおよびPDFデータを指定フォルダに格納する一連の手順を自動化させています。
実際にこのコードを業務で使っておりますので、皆さんが使用する際にも、このコードをコピペして活用できると思います。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import json
from selenium.webdriver.common.action_chains import ActionChains
from time import sleep
import os
import time
import shutil
# 格納フォルダの指定
movebase_dir = "C:/Users/Username/Documents/経理ファイル"
# ダウンロードフォルダパス指定
downloadsdir_path = "C:/Users/Username/Downloads"
# Chromeオプションを設定
options = webdriver.ChromeOptions()
options.add_experimental_option('detach', True) # ブラウザが閉じないように設定
# 印刷設定
options.add_experimental_option('prefs', {
"printing.print_preview_sticky_settings.appState": json.dumps({
"recentDestinations": [{"id": "Save as PDF", "origin": "local"}],
"selectedDestinationId": "Save as PDF",
"version": 2,
"isLandscapeEnabled": True,
"isHeaderFooterEnabled": False,
"isCssBackgroundEnabled": True
}),
"savefile.default_directory": downloadsdir_path # PDF保存先を指定
})
options.add_argument('--kiosk-printing') # 印刷を自動実行
# ChromeDriverのサービスを設定
cService = Service(executable_path='.\chromedriver.exe') # クロームドライバーが保存されているフォルダを指定
driver = webdriver.Chrome(service=cService, options=options)
actionChains = ActionChains(driver)
# 暗黙的な待機時間を設定
driver.implicitly_wait(10)
# 管理画面のログインページを開く
url_login = 'https://×××' # URLを指定
driver.get(url_login)
try:
# ID入力
text_box = driver.find_element(By.NAME, 'login_id') #ID入力の要素を指定
text_box.send_keys('×××')
sleep(5)
# パスワード入力
text_box = driver.find_element(By.NAME, 'password') #パスワード入力の要素を指定
text_box.send_keys('×××')
# ログインボタンをクリック
btn = driver.find_element(By.XPATH, '×××')
btn.click()
sleep(5)
# 施設選択(〇〇店)
btn = driver.find_element(By.XPATH, '×××')
btn.click()
sleep(5)
# 遷移先ページに移動
handle_array = driver.window_handles
driver.switch_to.window(handle_array[1])
# 入金明細をダウンロードする
btn = driver.find_element(By.XPATH, '×××')
btn.click()
sleep(5)
#格納フォルダに移動、リネーム
data = "110_〇〇店_入金明細.csv"
files = os.listdir(downloadsdir_path)
path_dir = os.path.join(downloadsdir_path,*files)
print(path_dir)
move_dir = os.path.join(movebase_dir,data)
shutil.move(path_dir,move_dir)
# PDF保存
WebDriverWait(driver, 15).until(EC.presence_of_all_elements_located) # ページ上のすべての要素が読み込まれるまで待機
driver.execute_script('window.print()') # 印刷を実行
time.sleep(10) # ファイルのダウンロードのために10秒待機
#格納フォルダに移動、リネーム
data = "110_〇〇店_入金管理画面.pdf"
files = os.listdir(downloadsdir_path)
path_dir = os.path.join(downloadsdir_path,*files)
move_dir = os.path.join(movebase_dir,data)
shutil.move(path_dir,move_dir)
# ブラウザを閉じる
driver.quit() # ブラウザを閉じる
except Exception as e:
print(f"エラーが発生しました: {e}")
# スクリプト終了を防ぐ
input("終了するには Enter キーを押してください...")
ダウンロードしたファイルの名前を変更し、所定のフォルダに格納する方法はこちらの記事で詳しく説明しています。
Python Selemiumで経理業務を効率化:ダウンロードファイルのリネームと所定フォルダへの移動を自動化
おわりに
Python Seleniumを活用すると、Webページからデータを取得することが多い経理業務を大幅に効率化することができます。
上記説明した方法の他、画面をスクリーンショットして保存する方法もこちらの記事で説明しています。
Pythonで経理業務を効率化 Webページへログインし、スクリーンショット・保存を自動化する方法と実例
経理業務の負担を軽減し、業務の効率化を進めるために、ぜひこの方法を活用してください!


コメント